 征信宝官网
征信宝官网来源于公众号“ 代码拾荒者”,作者郑丽彬 征信圈点评
个人征信发牌照了,就1张!曾几何时,在2017年全国工商登记中,征信字样的企业多达50多万家,目前能做个人征信的只有这2家了。
“给征信插上区块链的翅膀”,可能是其它这些“征信”公司目前最需要作出的选择了。君不见,原来获准筹备的8家,“巨头们”已经做出了baas;“新贵们”开始宣传自己转型做区块链技术;“务实者”默默的在招聘区块链的技术人才。
从场景驱动的“互联网金融”,转型到技术驱动的Fintech也是符合时下国家各项金融监管政策的大方向,正确的选择!
“故事”听了很多,没听到实际“应用”;
技术名词学了很多,没学到技术产品;
PPT看了很多,没见到过解决方案;
文章从央行征信系统局限谈起,提出了结合区块链的解决思路,同时建议了具体的应用场景,很值得一读,征信圈把原文前面大段介绍区块链基本概念的略去了,有兴趣的可以点击文末的链接阅读原文。
征信圈觉得:
① 区块链征信系统基于Hyperledger Fabric架构会比较符合现有监管体制的要求;
② 文末关于区块链的奖励机制,把金融机构征信数据报送、异议处理挂钩征信查询费用是个很好的思路,建议监管认真考虑。
文章中谈了央行征信系统的现状和一些案例系原文所列,通过思考区块链技术的特点,提出了改进的思路和具体应用方法,虽然不一定准确,也不见得真正落地,但建议“那谁谁”兼听则明,听听新技术下的思考,别明天又把这篇文章“关了小黑屋”;
1、征信系统的应用历程和现状
中国征信系统是由人民银行主导,建立集中企业及个人信用信息档案库,采集来自各金融机构、企事业单位等机构的企业和个人信用信息,并对外提供有条件查询。
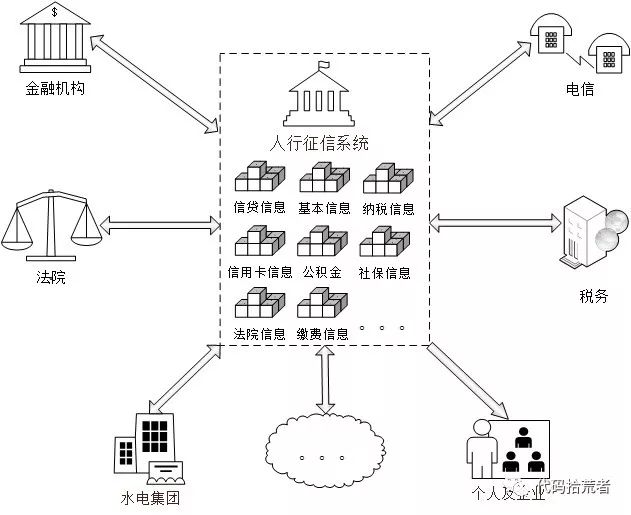
图8:征信系统拓扑图
1.1 沃尔沃汽车金融的征信系统使用历程
沃尔沃汽车金融(中国)有限公司作为小微金融机构,人行在2010年开始才给其提供页面查询征信报告功能,同时并未给其提供报送信用数据的接口。而基于页面查询征信报告有诸多缺点:
(1)操作效率低下,需要手工登录并录入证件信息查询,查询结果只能通过人为判断、分析来把控客户信用风险。
(2)成本昂贵,2011年查询征信报告,当天查询企业征信报告一份260元,个人征信报告一份8元。而征信数据短期内更新频率不高,多次查询容易产生较高费用。
(3)数据利用率低,基于html页面的非结构化征信报告,不便于数据分析,不便于数据共享,影响风险管理系统和业务系统的客户信用风险分析。
因此,在2011年时,沃尔沃开始进行内部征信系统建设,采用后台模拟网页登录方式,从人行征信系统抓取征信报告,并对html报告进行解析入库。2013年人行开放接口查询,以及2015年将小微金融机构接入征信系统,沃尔沃汽车金融也开始进行相应的改造。
1.2 建行的征信系统使用历程
建行作为五大国有商业银行之一,享有最早使用征信数据,及时跟进和使用新服务的各项便利。从2006年向人行接口报送数据,通过页面查询征信报告。2013年
同步实现征信报告接口查询。2015年人行开始征信系统二代建设,近期也选取了建行为试点单位,计划于2017年10月试运行,2018年5月正式投产。
征信二代相较于征信一代,主要在采集时点、数据组织内容、报文格式、数据纠错等方面进行细化和优化。但是仍未广泛接入来自社会较全面的信用数据,征信
信息仍存在覆盖不全的问题,比如缺少网贷、证券等信用数据,不能完全满足对客户信用风险进行全方位把控的需求。
1.3 征信系统现状
作为中心服务的征信系统,每一次接口变动、系统改造以及运行状况都对外围系统有很大影响。比如2017年3月份某国有银行通过人行接口批量查询5万笔客户征
信报告时,因征信信息较多,结果压垮人行征信系统导致其他征信机构查询受到影响。同时由于接入的征信信息不全,无法对外提供完整的征信信息,需要芝麻
信用、微信征信、鹏远征信等征信市场上其他松散、孤岛的征信数据进行补充。在社会信用体系建设中,打造覆盖全社会各行业的征信系统仍面临诸多挑战:
(1)数据膨胀:目前的征信数据主要以信贷、信用卡业务为主导,随着社会信用体系的建设,更多行业以及互联网的信用数据将纳入到征信系统,数据范围、数据采集点、数据增长速度对征信系统的大数据存储是一个巨大的挑战。
(2)用户数暴增:随着国家对征信知识的宣传,征信信息的普及,国民对征信的重视,使越来越多的企业、个人、组织都加入到征信体系中。用户数和并发数的暴增,容易使系统出现各种并发问题,对系统的稳定将会造成很大的影响。
(3)技术壁垒:从2006年个人、企业征信系统开始运行,2009年对软硬件配置、数据存储能力进行升级。但是随着通信技术和征信业务的发展,原有的架构不能满足现有需求,于是2015年开始启动征信系统二代建设。数据量和用户数的暴增,系统容易呈现复杂的瓶颈问题,传统软件技术架构就会陷入了需要不断地对软硬件进行升级的怪圈中。
2 区块链应用于征信系统的可行性分析
2.1 征信系统业务场景特点分析
征信系统主要是收集、存储、提供征信数据,并衍生出行业、区域风险分析、关联查询、风险预测等相关的增值服务,跟其他的系统相比有很强的个性和特色:时效性:相对于比特币交易,征信系统对数据的时效性要求并不高,目前大部分商业银行都是在开户、结清等事件点以及期间日终、月终等数据采集点批量上报征信数据,并以T+1方式次日完成更新。区块链是由后续区块的加入,以最长分支确定当前区块生效,每个区块生成时间大概10分钟, T+1时间是足以将区块更新到各个节点。
扩展性:征信系统架构必须具有前瞻性,能支撑起社会信用体系建设中出现的数据膨胀和海量访问,区块链技术避免了传统服务器架构需要不断升级扩容的短板,当源源不断的新节点加入,在增加客户端请求和数据量的同时,也分摊了服务器端处理请求和数据存储的负荷,实现了系统的自动扩展。
隐私性:征信信息涉及到个人隐私,除了监管机构外,任何其他机构和个人非经授权不允许查询他人的征信报告。目前大部分商业银行都是线下或是系统外记录客户授权信息,查询征信报告时人行征信系统并未实时授权验证,而是事后通过大数据分析和反欺骗等手段挖掘出非法查询账户。而区块链是去中心化、开放的,鼓励征信活动参与者积极参与和共同维护,这就让参与者在线上相互间进行授权变得更为可行和便捷。
稳定性:基于中心服务的征信系统,在升级扩容维护的窗口期或是系统出现性能问题时,都会影响到外围系统的正常访问和使用。而去中心化的区块链技术,弱化了与具体节点的系统间耦合,屏蔽了关键节点的影响范围,为实现7*24小时不间断服务提供更好的保障基础。
2.2 以太坊和超级账本的适用性分析
以比特币为代表的区块链,在应用于其他业务场景时因缺乏灵活性或是个别不足导致无法满足于复杂的应用需求。因此以智能合约和权限控制为特点的以太坊和超级账本进一步推动了区块链技术的发展。
以太坊:智能合约即是通过程序脚本定义的约定,通过内部的虚拟机执行图灵完备的脚本语言,实现了符合一定条件时动态执行合约,从而增加了系统灵活性以满足更多的特殊业务需求。征信系统主要是采集信用数据并对外提供查询,本身不需要复杂的业务逻辑判断和处理,所有以太坊对于征信系统并不能突出本身的优势或是带来更多的帮助。
超级账本:超级账本有很多特性适合应用于征信系统,如身份识别服务和策略管理服务,方便进行身份验证和权限授权。但是采用多管道进行物理隔离的权限控制,难以实现信用主体对征信报告授权查询这样个性化、细粒度的授权策略和权限控制。同时对于征信系统海量数据存储,超级账本并没有提供一个良好的方案。
针对征信系统的特殊业务场景,采用基于去中心化的区块链原理,同时借鉴其他相关技术,覆盖区块链技术没有实现到的薄弱环节,取长补短,以灵活解决征信系统中出现的各种特殊业务需求。
3 基于区块链的征信系统设计
3.1 P2P网络架构
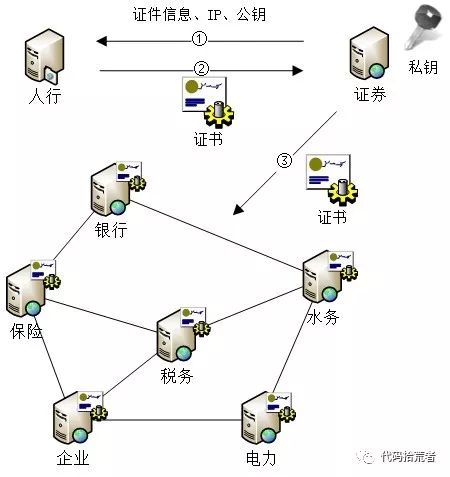
图9:征信系统P2P网络结构
征信活动的参与者可分为三类:人行、征信机构、信息主体。
人行:作为征信业务的监管机构,负责授权、管理协调其他参与者进行有序、规范的征信活动,本身无需参与区块链的维护。
征信机构:征信信息的报送机构,如银行、税务局等,具有报送权限以及查询经过授权的征信报告。是区块链活动的主要参与者。
信息主体:征信信息的描述对象,是被征信的企业或个人。不具有报送权限,主要查询自己的征信报告。在区块链活动中主要扮演生成区块和备份数据的角色。
人行跟其他活动参与者通过对等网络方式进行连接,任何机构和个人都可以加入到网络中,但是只有经过人行认证后颁发证书,才能在对等网络中参与征信活动。加入步骤如下:
(1)申请加入的主体(即征信机构或信息主体),在本地生成秘钥对,将公钥、证件信息、服务器IP等信息报送给人行
(2)人行审查后根据公钥生成、颁发证书,证书内容包含如下信息:
申请主体的公钥
人行的公钥
权限类型(1-报送和查询,2-查询)
数字签名,即将申请主体的公钥、人行的公钥、权限类型,通过人行的私钥进行签名
(3)申请主体参与征信活动时,将证书传给其他节点,其他节点通过人行公钥对证书进行签名验证,从而验证其身份和权限。
3.2 报送征信数据
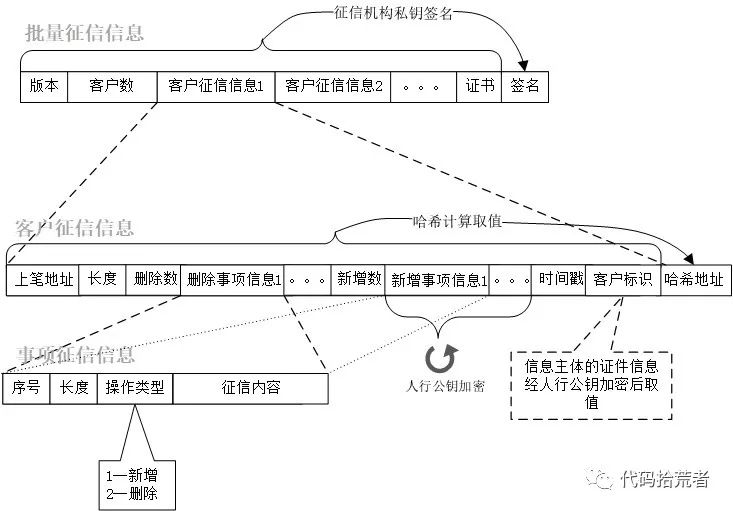
图10:报送征信数据结构
3.2.1 事项征信信息
事项征信信息是根据信息主体与征信机构发生的业务,在数据采集点提取出相应的业务信息,每一笔事项征信信息对应一笔业务,是对信息主体的征信信息最细粒度的描述,主要分为新增报送和删除报送。
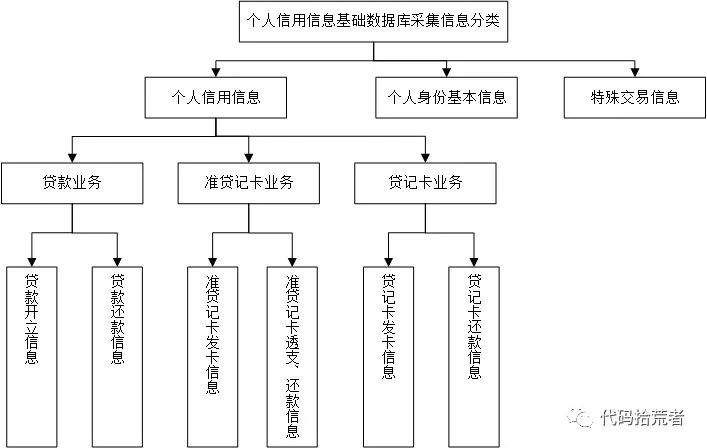
图11:个人征信内容
(1)新增报送:以目前银行报送个人征信信息为例,征信内容如图11,针对不同业务以及同一业务下不同的指标内容,人行可以下发格式校验规则库。银行根据业务系统提供的业务数据,加工出对应格式的事项征信信息,并通过人行规则库校验后才能进一步加入到该信息主体的客户征信信息里。
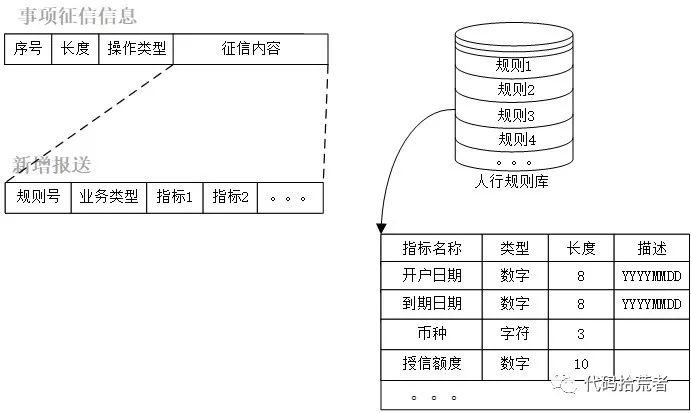
图12:新增事项征信信息
(2)删除报送:当信用主体对自己的征信报告提出异议,经征信机构核对后确认历史报送征信信息不正确,则可以发起删除报送。删除报送内容需要指定历史征信信息的地址位置。
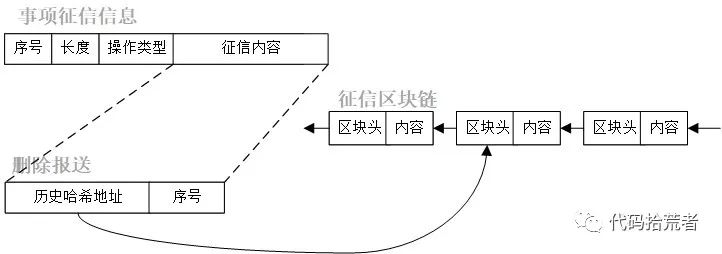
图13:删除事项征信信息
3.2.2 客户征信信息
客户征信信息是征信机构在数据采集点上,将同一信息主体的所有事项征信信息进行合并汇总。比如征信机构的某个客户既有信用卡业务又有贷款业务,则客户征信信息为信用卡事项征信信息和贷款事项征信信息的合并拼接。客户征信信息需要附上该信息主体在区块链上最后一笔哈希地址,并且新增的事项征信信息需要经过人行公钥加密,同时附上该信息主体的证件信息经人行公钥加密后产生的“客户标识”。最后经过哈希计算生成哈希地址,组装成完整的客户征信信息。
3.2.3 批量征信信息
批量征信信息是指征信机构在数据采集点上,将要上报的所有信息主体涉及到的客户征信信息进行合并汇总,并附上征信机构的证书,然后对上报的内容进行签名,组成完整的批量征信信息。
批量征信信息报文长度有可能较大,可先进行压缩并附上压缩算法,最后在对等网络中进行广播。
3.2.4 失败重发
由于区块链的共识机制,征信机构广播的批量征信信息可能最终没被成功加入到区块链中,征信机构需要在一段时间后进行核查,如果确认失败则需要重新获取并更新客户征信报的上笔地址,并广播到网路中。
3.3 验证征信信息和生成区块
3.3.1 验证征信信息
P2P上的节点接收到批量征信信息后,除了加密后的新增事项征信信息无法校验,其他信息内容都需要进行验证。验证的步骤如下:
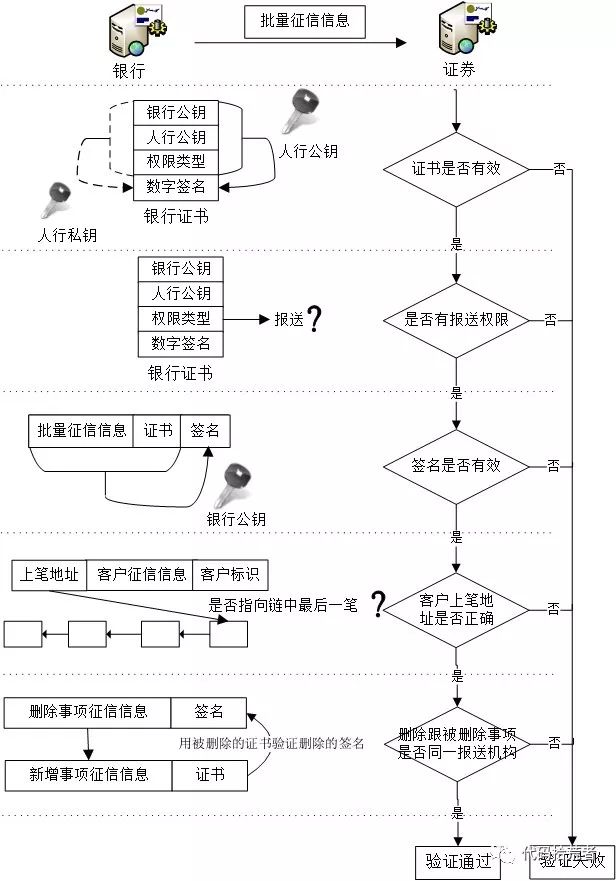
图14:验证批量征信信息流程
(1)验证批量征信信息:主要验证批量征信信息的证书是否人行颁发并且有效、是否有报送权限、数据是否未经修改。
(2)验证客户征信信息:验证客户征信信息中的上笔地址是否为该信息主体在当前区块链中最后一笔哈希地址。
(3)验证删除事项征信信息:通过删除事项征信信息找到要删除的历史新增事项征信信息,用历史的征信机构证书验证当前征信信息的签名,如果验证签名通过说明是同一征信机构,该删除事项征信信息有效。
(4)新增事项征信信息由征信机构负责并保证其准确性,人行通过异常处理、对账审计和奖惩机制等手段约束征信机构的报送操作和保证其数据质量。
3.3.2 生成区块
网络中所有的节点都有权限生成区块。节点收集所有验证通过的批量征信信息,通过工作量证明并以大约10分钟的速度生成区块,并向其他节点广播。生成区块的原理跟比特币挖矿类似,部分方式根据征信的特点进行调整:
(1)取消区块内容第一笔交易为挖矿所得的奖励机制,改成通过降低查询征信报告费用的方式进行奖励。
(2)比特币对每笔交易收取一定手续费的方式,避免恶意发送交易。为避免征信机构恶意发送批量征信信息,每生成区块时间段内,发现同一征信机构出现多笔报送记录的,废弃该征信机构本次发送的所有批量征信信息。
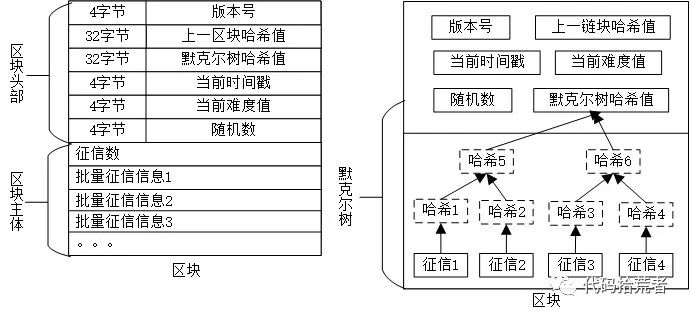
图15:征信区块结构
生成区块的大致过程:
(1)将收集到的报送征信信息,经验证通过后,过滤掉同一征信机构出现多笔的批量征信信息,然后加入到区块主体中
(2)区块主体中的批量征信信息列表,通过默克尔树算法生成默克尔哈希值,跟其他字段信息组成长度为80字节的区块头部。
(3)将区块头部内容,经过两次哈希计算后,结果值如果小于以数位0字节开头的目标值,则区块头有效并结束,否则重新生成随机数并重新计算,直到生成有效区块头。
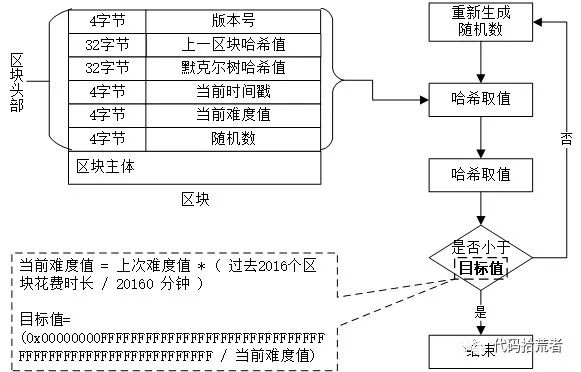
图16:生成区块流程
生成有效区块时需要大量的CPU计算,最先生成的区块广播到网络上,因而更容易被优先加入到区块链中,并通过后续产生的区块进一步巩固。以提高恶意节点伪造区块的成本。
3.4 维护区块链和数据存储
3.4.1 维护区块链
节点收到在网络上广播的区块,验证区块是否有效:
1、该区块的哈希值是否小于目标值
2、该区块的“上一区块哈希值”,是否指向当前区块链的最后一个区块。
验证通过后加入到现有的区块链,但是此时还不能确定是否生效,需要等到下一个区块的加入才能确定。比如同时收到来自不同节点广播的区块,经过验证都是有效,同时加入到区块链则产生分支。直到下一个区块的加入,以最长分支的区块确定生效,其他分支的区块则废弃。如图4:区块链分支。
3.4.2 数据存储
比特币交易中主要信息是钱包和交易金额,单笔交易携带的数据量很小,但从2009年运行至今,完整的历史交易账本数据已超过80G。而征信系统中,每一笔征信明细,都会附带相关的业务指标项,数据量远远超过比特币的单笔交易。随着更多行业的征信数据加入,数据存储是考验系统能够长期稳定运行的关键。
每个P2P节点存储完整的征信区块链数据是不现实的,摩尔定律中硬件升级的速度是远远赶不上征信数据的膨胀。区块头部字节长度固定,区块增长速度稳定,所以每个节点可以保留由区块头组成的区块链。而区块主体包含了征信信息明细,数据量较大,征信系统可以采用一致性哈希算法的方式进行存储,每个节点只需要根据一定的规则存储其中的一小部分数据,所有节点组合后提供完整的征信数据,同时采用一定的备份策略保证数据安全。
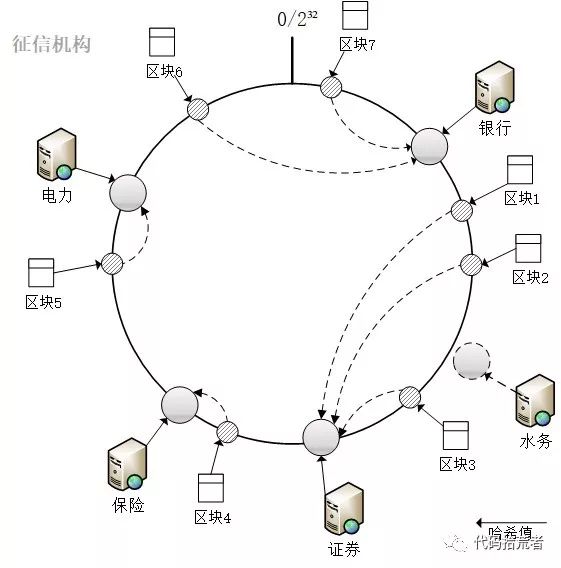
图17:一致性哈希算法存储
征信主体节点加入退出比较灵活,对一致性哈希算法效率有一定影响,而征信机构节点相对比较稳定,目前征信机构加入和退出征信系统都需要提前上报人行。
所以征信机构和信息主体分别进行一致性哈希算法存储。并以征信机构为主导,信息主体为备份,提高数据存储的可行性和安全性。以征信机构为例:
(1)存储策略:所有的征信机构节点根据服务器地址经哈希取值,映射到0到2³² -1的环中。当节点从网络中接收到新的区块时,区块头部加入到区块链中,然
后判断本节点服务器地址哈希值是否距离区块哈希值顺时针最近的。如果是则存储区块主体,否则废弃该区块主体。
(2)备份:备份的数目需要事先确定好并固定不变的,否则一旦变动就会造成之前的存储位置失效。比如备份数位3,新增区块时,需要存储的位置为hash(区块)、hash(区块)+ 2³²* ¼、hash(区块)+2³² * ½、hash(区块)+ 2³² * ¾。
(3)加入:新的征信机构节点加入时,从网络上获取完整的只含区块头部的区块链,遍历区块链的区块哈希值,判断哪些是应该本节点存储的区块主体,从逆时针方向最近的节点获取并存储。
(4)退出:当网络中发现某个节点失联或是主动申请退出时,则需要通知逆时针方向最近的节点,遍历完整的区块链,判断哪些是本节点应该存储的区块主体,从备份的节中获取并存储。如保险节点退出,则电力节点从备份节点获取区块4的副本并进行存储。
3.5 查询征信报告
比特币钱包本质上是用UTXO(未花费的输出)来体现,即交易链中最后一笔交易的输出地址。而在征信系统中的UTXO则是征信主体在区块链中的最后一笔客户征信信息的哈希地址,通过UTXO可以在区块链中往前追溯出该信息主体的所有征信信息。详细的查询步骤如下:
(1)被查询的信息主体用私钥生成授权查询证书并发送给征信机构
(2)征信机构将被查询信息主体的证件信息经人行公钥加密生成客户标识,在UTXO库中查询最后一笔客户征信信息的哈希地址,然后在区块链中往前遍历查询出所有涉及到的区块头部(如果是只需要查询近5年征信信息,可根据区块头时间戳判断一旦超过5年则不继续往前遍历),过滤掉被删除的区块头部,并从P2P网络中通过区块哈希值在一致性哈希存储中获取区块主体。
(3)将完整区块主体的加密征信报告、授权查询证书、征信机构的证书及签名压缩发送给人行。
(4)人行解压后,验证报送机构证书、授权查询证书和查询期限,通过后经过人行私钥解密并返回解密后的征信报告给征信机构,同时记录查询日志。
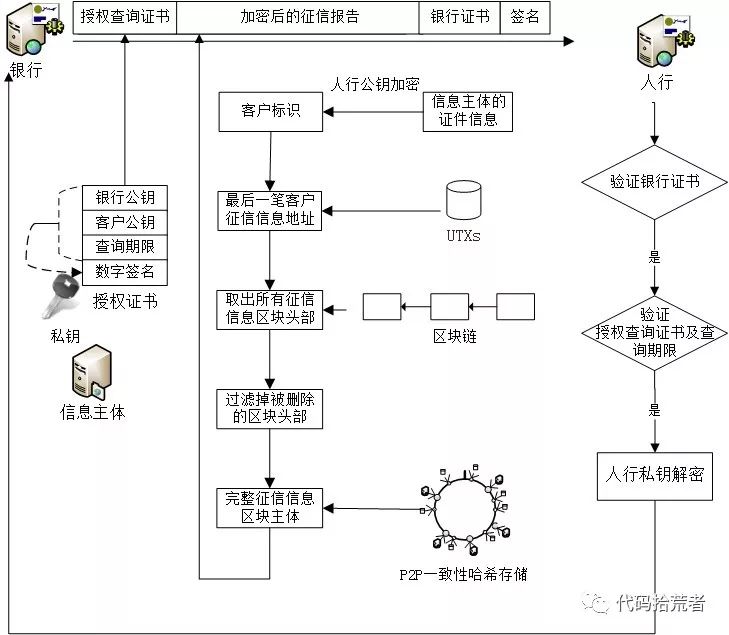
图18:查询征信报告流程
3.6 奖惩机制
为鼓励更多组织和个人加入区块链,共同维护征信区块链,需要一个良好的奖惩机制,对报送数据不规范、不准确、或是恶意报送的行为进行惩处,对积极生成区块、分摊备份存储的进行奖励惩罚措施:
(1)经人行对账审计或是信息主体提出异议,核查确定征信机构报送的征信内容不准确,数据格式不正确,次数较多的征信机构在查询征信报告时适当提高查询费用。
(2)因恶意报送征信数据、恶意退出P2P网络的征信机构,可以下发黑名单库,拒绝其报送数据和查询征信报告。
奖励措施:
(1)只有加入P2P征信网络中,才可以经授权进行查询征信报告,或是查询费用比其他间接方式查询还低
(2)生成区块较多的征信机构,在查询征信报告时适当降低查询费用
4 系统不足及应对措施
本设计方案最大的不足是受征信信息加密的影响,其他节点在生成区块时无法校验其格式的正确性以及人行需要承担解密工作。格式错误问题可以通过奖惩机制约束征信机构报送前进行严格校验,以及异议处理进行事后数据修复。人行对征信报告解密会消耗一定的CPU资源,在查询高峰期时可以通过请求优先级、队列、异步、增加CPU资源等方式降低系统负荷。
5 结束语
本文主要探讨了区块链技术应用于征信系统,可以解决传统集中处理的瓶颈和不足,人行可以从接收、存储、提供征信数据等相关服务中剥离出来,只需负责提供数字证书和征信报告解密,最大程度地低降人行系统服务压力。通过所有征信参与者的共同维护,可以提供一个更安全、更稳定、更容易扩展的征信系统。同时具有很强的前瞻性,在不需要升级架构和扩容软硬件的情况下,满足未来复杂多变的处理能力和负载要求。
从设计方案也可以看出,目前区块链技术还不是非常成熟,在应用于各种去中心化的业务场景中,无法完全有据可循、有条可依地解决各种个性化需求问题,需要根据实际情况并结合区块链原理做相应的改造,借鉴其他技术来弥补区块链的各种不足,以打造出能够真正落地,可行并且更加健壮完善的去中心化应用系统。
